使用NodeJS进行截图
需求
工作中,产生了这样一个需求:想要访问一个网站,并在3个及以上的URL下全屏截图保存到本地。初步了解了一下这方面的现成方案:
- 使用Chrome –headless
- 使用puttepeer,这是方案1的进阶版
但是很可惜,经过进一步的与对方沟通,他们要求不仅是把网页截图下来,还需要把浏览器,包括地址栏都要截取下来,防止上级部门怪罪下来说他们伪造截图。这样上面的两种方法就都行不通了——它们都只能截取网页本身,也就是<html> …… </html>标签之间,渲染后的图片。
想着本来都已经把puttepeer安装上了,也懒得转Python了,索性就NodeJS三两下搞定吧。
依赖项及说明
1 | ├── cheerio@1.0.0-rc.11 |
- 对方事后要求在Windows 7系统上运行,无奈只能选择NodeJS v13.x进行开发。(NodeJS从v14开始不再支持Windows 7)
- cheerio:HTML解析,可以加载远程页面,也可以加载HTML字符串。由于有几个页面需要先爬取URL再截图,故需要此包。
- open:一个封装后的包,功能主要是跨平台打开浏览器及URL,或者是打开文件,我的程序用来打开浏览器。
- screenshot-desktop:截图工具包,只需要一个
screenshot(filename)就可以把截图保存下来,非常方便。 - sync-request:此包实际上已停止维护,且作者也建议使用
then-request,但由于需要等待网页加载完成再进行截图,最方便的方式就是使用同步请求,等请求返回,拿到一组URL后,再逐一打开网页并截图。
工作流
- 一些常量定义及初始化工作,如保存截图的文件夹的创建。
- 打开URL1,等待一个延时后截图并保存。
- 打开URL2,等待一个延时后截图并保存。
- 爬取URL2中的页面数据,提取出后续需要截图的URL列表。
- 逐一访问URL列表中的地址,重复步骤2或3。
- 全部截图完毕后,打开一个finish.html页面,提醒用户工作已全部完毕。
一些意外
由于这类网站的一贯作风,网页写得十分地凑合。前面提到的URL2是一个列表,里面有至多12行数据,再多就通过底部的分页栏进行分页。但在访问这个页面的时候,其实服务器就把全部数据都从数据库中取出来,以Javascript字符串的形式输出到HTML页面上,甚至已经是html代码了,见下图: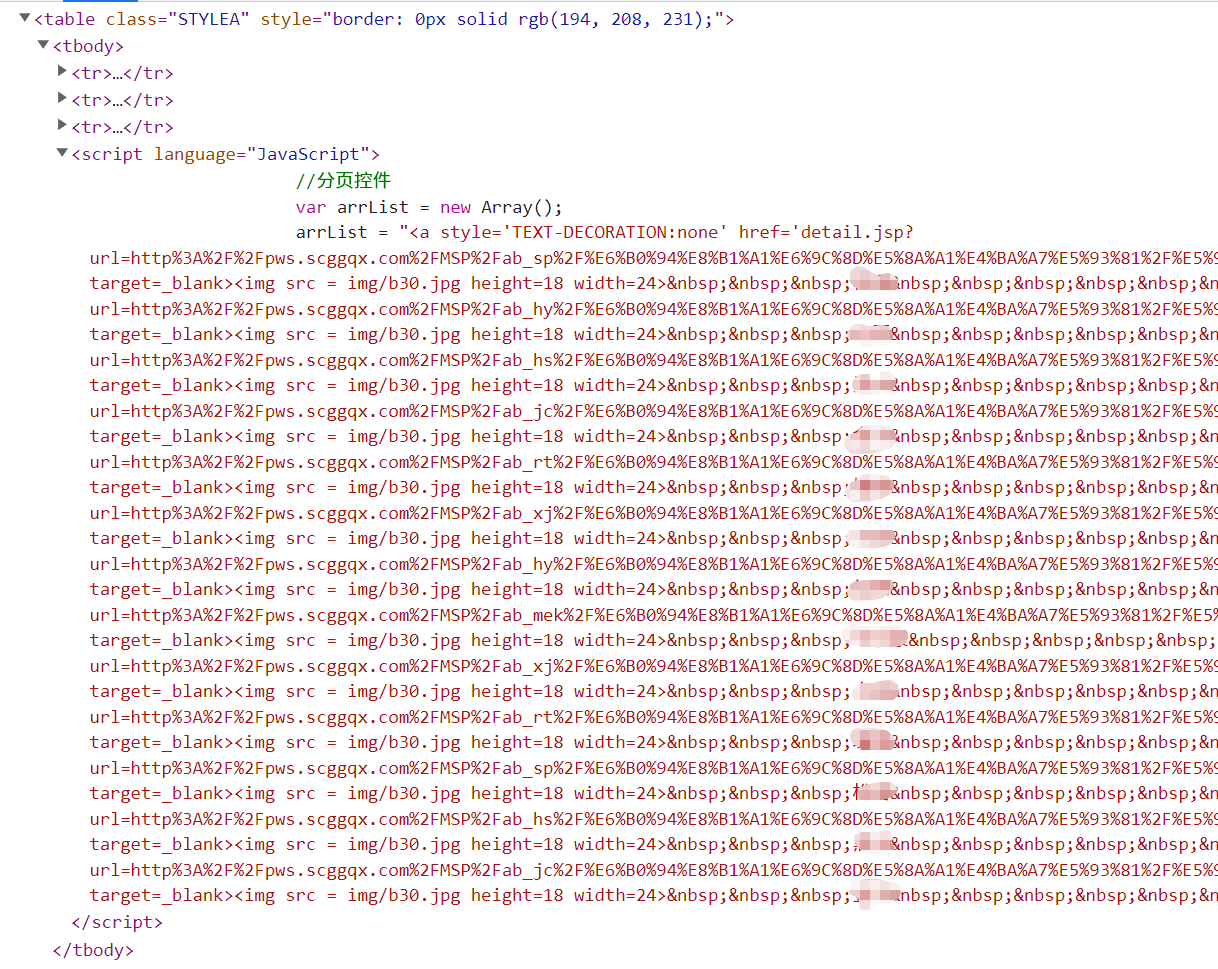
而我后续要访问的页面就在这里面,即<a href="xxx"></a>,没办法,只能把这段字符串形式的HTML代码抓取下来,放进cheerio里面把URL提取出来再进行后面的操作。